Along with Route 53, S3 is probably the Amazon service I have the most prior experience with, albeit that’s not a lot. I’ve previously used S3 for static website hosting to make a sample website resume, so I have a rough idea of what it’s used for and how it works in general. At it’s most basic level, S3 is just unstructured storage for objects like images, documents, etc. It’s not block storage like you would use for filesystem, and there’s no attached operating system or processing or anything like that… it’s just a dumping ground for objects. All these objects in S3 go into containers called “buckets.”
Creating a Bucket
To start messing with S3, we first log in to our AWS account. For this demo, I’ve logged in to my General account. Next, I choose S3 from the list of AWS services to make it to the S3 dashboard. From the dashboard, clicking on the “Create a bucket” button brings us to the interface below, where we name the bucket with a globally unique name and select a region. I’m in the eastern US, so us-east-1 is my natural choice.
Bucket Security
If you follow news on data breaches, you’re going to frequently see data breaches blamed on leaky S3 buckets - buckets where the administrator has configured an S3 bucket to be publicly available rather than requiring authentication. Because of this, my impression of S3 before using it was that it must be hard to keep private. Either in spite of all those breaches or because of those breaches, AWS makes S3 buckets secure by default. As you can see in settings below, the default setting for an S3 bucket is to block all public access. The double-whammy is that even if you uncheck this box, the bucket is still private until you explicitly allow public access. Unchecking the box below only makes it possible to provide public access to the bucket. When you uncheck that “block all public access” box, it then prompts you to check a box acknowledging that you know that unchecking the box makes it possible to expose the bucket publicly. After setting up a few buckets, it’s easy to see that leaky buckets can happen, but not through any fault of AWS architecture.


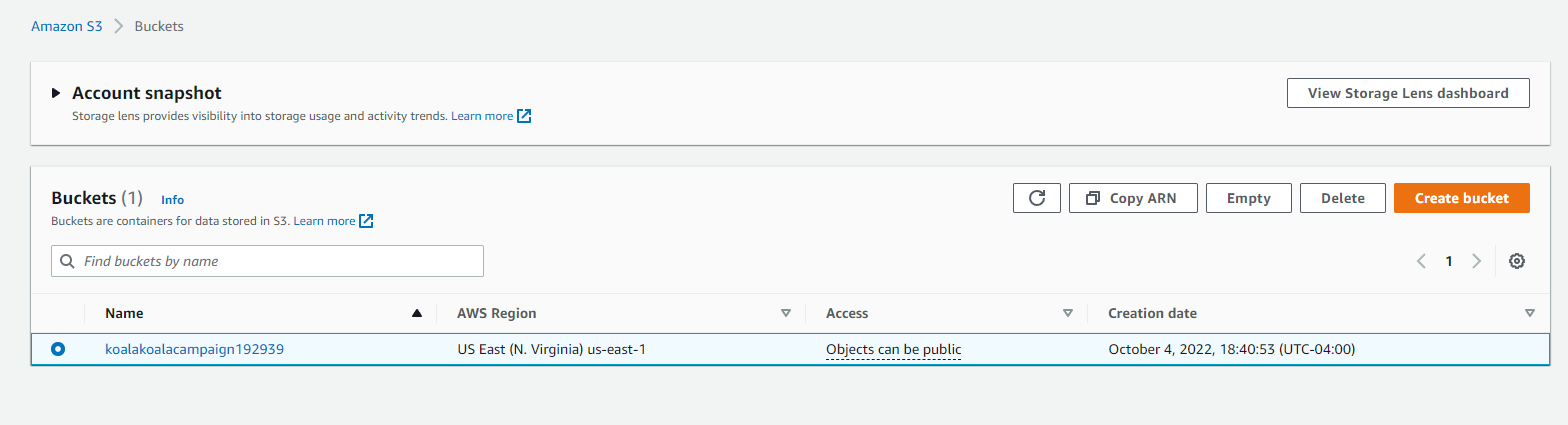
After creating the bucket, it will show up in the S3 dashboard. Because we unchecked the Block public access box, note that access is listed as “Objects can be public.”

To add objects to the bucket through the AWS GUI console, click on the bucket name on the dashboard and then click the “Upload” button. It will prompt you to add files from your computer.

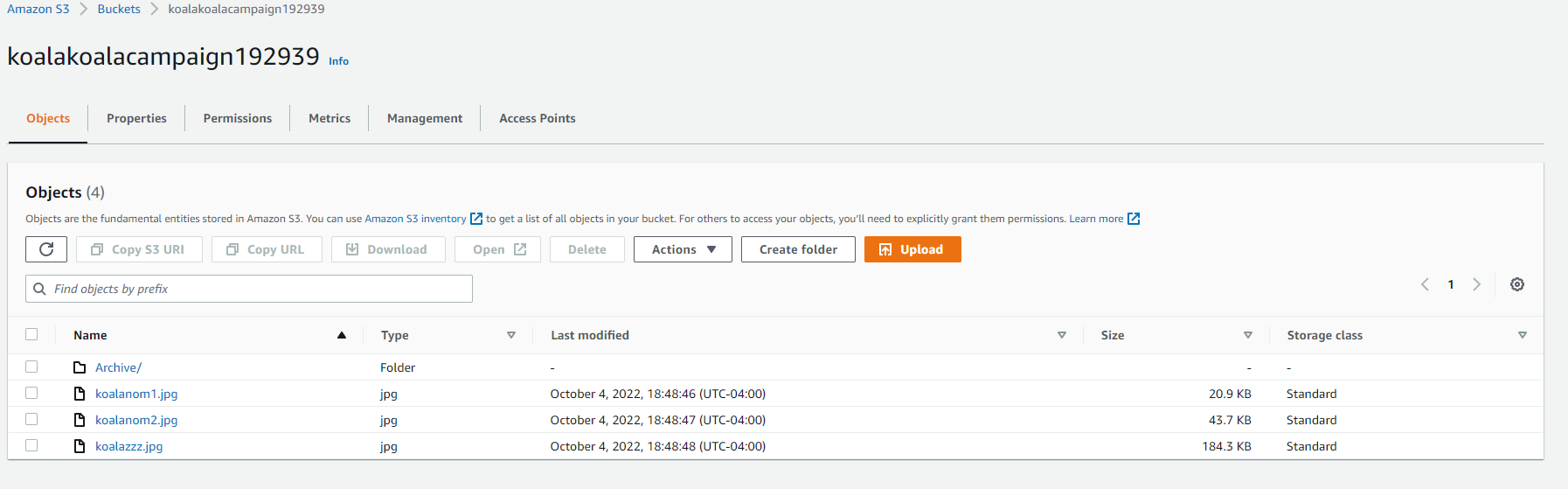
For our example, I’m uploading 3 image files - koalanom1.jpg, koalanom2.jpg, and koalazzz.jpg.

Object Versioning
Another detail to note is that if you click on the bucket’s “Properties” tab, you can enable versioning. That way, if you add new versions of an object, you’ll maintain a history of the prior iterations.

Objects vs Files
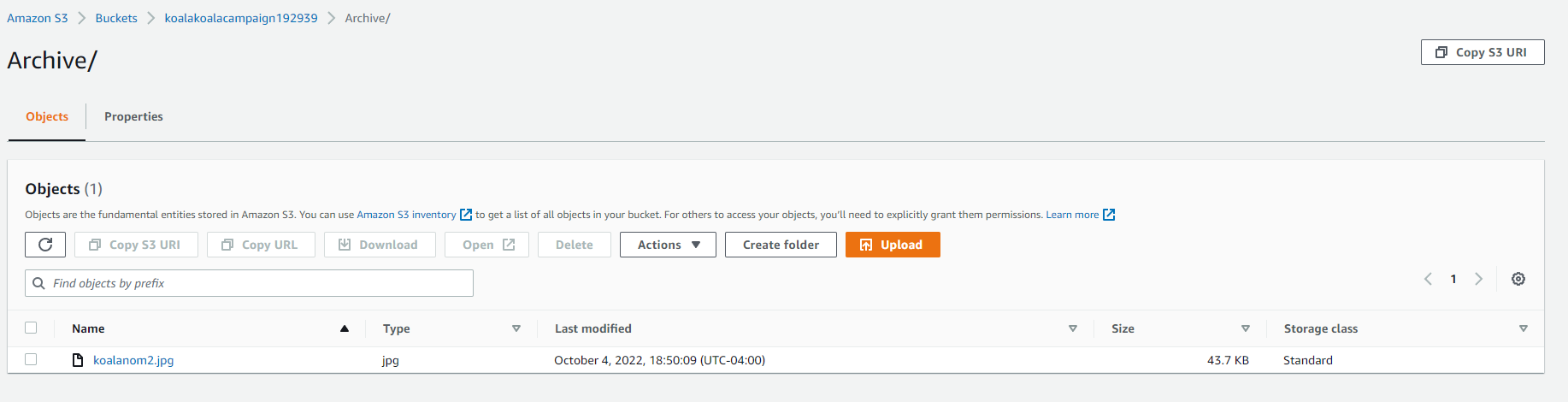
When dealing with object storage in S3, it LOOKS like a file system. There are even structures that look like a directory structure. However, this is all an illusion. Everything in your bucket is flat. There are no directories or sub-directories. You can, however, for organizational purposes, create filename prefixes that LOOK LIKE directories and sub-directories. In the example below, I’ve made an object with the type “folder” called archive/ and moved koalanom2.jpg inside of it. Programmatically, though, koalanom2.jpg isn’t really in a new directory… It’s really been renamed Archive/koalanom2.jpg. If we want to take the abstraction a step further, as far as S3 is concerned, the objects stored aren’t even really treated as files. As far as S3 is concerned, Archive/koalanom2.jpg is a collection of bits and “Archive/koalanom2.jpg” is just a string that works as the key to identify the object stored in the bucket.
Cleanup
This level of work in S3 falls under the free tier, but to keep up good habits and prevent future surprise billing, it’s time to get rid of our bucket.
As a safety precaution, you can’t delete a bucket that has objects in it, so we first have to Empty the bucket and then delete the bucket like below: